
谷歌风雨飘摇,市值蒸发数千亿美元!Gemini Spark能救场吗?
谷歌风雨飘摇,市值蒸发数千亿美元!Gemini Spark能救场吗?Transformer之父走了,诺奖得主走了,预训练核心走了——一周内,四个人离开谷歌。最新的一张牌Gemini Spark能挽回谷歌士气吗?
来自主题: AI资讯
9505 点击 2026-07-02 11:06
 搜索
搜索
Transformer之父走了,诺奖得主走了,预训练核心走了——一周内,四个人离开谷歌。最新的一张牌Gemini Spark能挽回谷歌士气吗?
一家只做Transformer专用芯片的创业公司成功流片,连带官宣了一串大进展: 不仅筹集到了8亿美元的资金,还喜滋滋获得了10亿美元的客户大单。

2026 年 6 月,大模型行业正在经历一场前所未有的「开源海啸」:英伟达放出了 550B 参数的混合架构模型,谷歌送出多模态的 Gemma 新版本,智谱用最宽松的协议全量开源了自家旗舰模型。
最近,谷歌连失两员大将。短短三天内,先是 Transformer 论文共同作者 Noam Shazeer 离开谷歌加入 OpenAI;紧接着诺贝尔奖得主、AlphaFold 负责人 John Jumper 转投 Anthropic 麾下。

AI 圈又迎来一次标志性的人才流动。就在刚刚,Transformer 论文作者之一,知名 AI 研究员 Noam Shazeer 在 社交媒体发文宣布,他将正式加入 OpenAI。

Transformer 依托强大的建模能力和 Scaling 效率在推荐领域被广泛应用于超长序列建模和生成式推荐等方向,
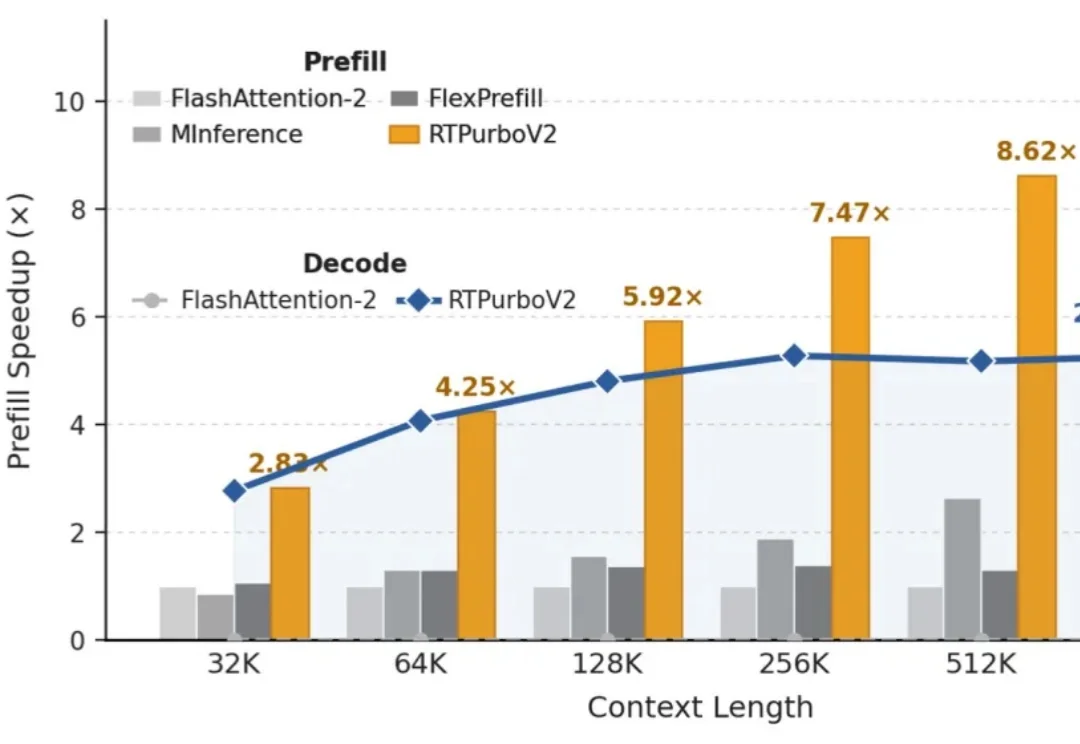
“Full Attention 正在被遗忘”

不扩上下文窗口、不换骨干架构、不做全参数微调 —— 只需要一个 8×8 的在线状态矩阵,就能让冻结的 Transformer 拥有真正的长期记忆。
“完全抛弃传统的代码编辑器,我直接告诉 AI 去修改代码。”

如果说扩散世界模型的瓶颈,是每一步去噪都要把同一个大 Transformer 再跑一遍,那么 WorldCache 的思路就是:不要再把所有 Token、所有时间步都当成同一件事。这篇工作把 “哪些内容适合缓存”和“哪些时刻必须重算” 拆开处理,在不重新训练模型、几乎不增加额外显存的前提下,把缓存真正做成了一套更贴合世界模型结构的推理策略。